Self-Service
With distributed software delivery teams, the key to scaling, is empowerment.
Many teams will need to create a lot of common software components, which will need to comply with regulations (Databases, Queues, etc)
Self-service is one solution to allow squads to create this components on demand, in a way that considers all the software qualities consistently
TL;DR;
While we scale up the number of Squads, they can use Self-service to create components in a way we can either automate/improve
- consistancy
- governance
- consolidation
- independance (delivery)
Background
For this we will need a problem, which will be common across multiple teams and services.
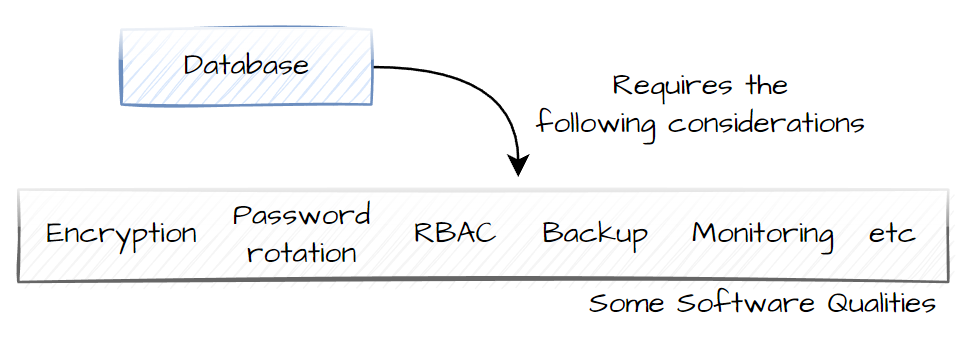
Lets take storing Data, we find across our services we need to
- store data using a document strcuture (JSON document).
- meet a number of regulations
- to support aread heavy scenario
- etc
the main thing is most of our services have a similar useage scenario (they are not looking at crazy extremes)
So we require a database (this may involve a cluster, a SaaS service, what ever.)
Which means we need to consider / design and build for a number of Software Qualities.
As we develop our solution across multiple Squads, we may fall into a couple of camps
possible solution 1
Every Squad owns the entire tech and pattern stack. which sounds awesome, as we have removed dependencies from them.
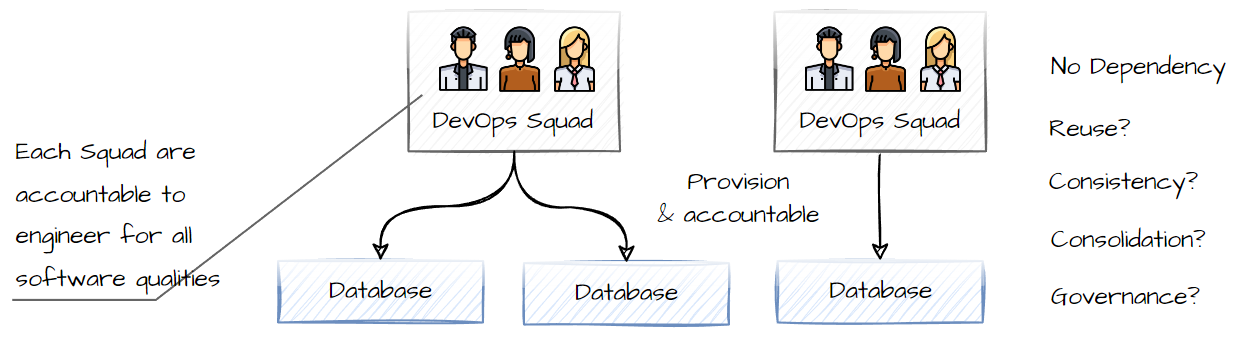
However this can lead to inconsistancy between squads, duplications to common problems and this imapacts effecientcy of delivery.
Taking our exmaple, we require a Database, Team A select Postgres, they have ownership, including ensuring all guard rails are met (Skills, RBAC, Encryption, Backup, etc).
possible solution 2
A central squad is setup to implement common components and patterns, they work with the community to develop solutions which the other Squads can build on. This allows for a reuse and consistancy between teams.
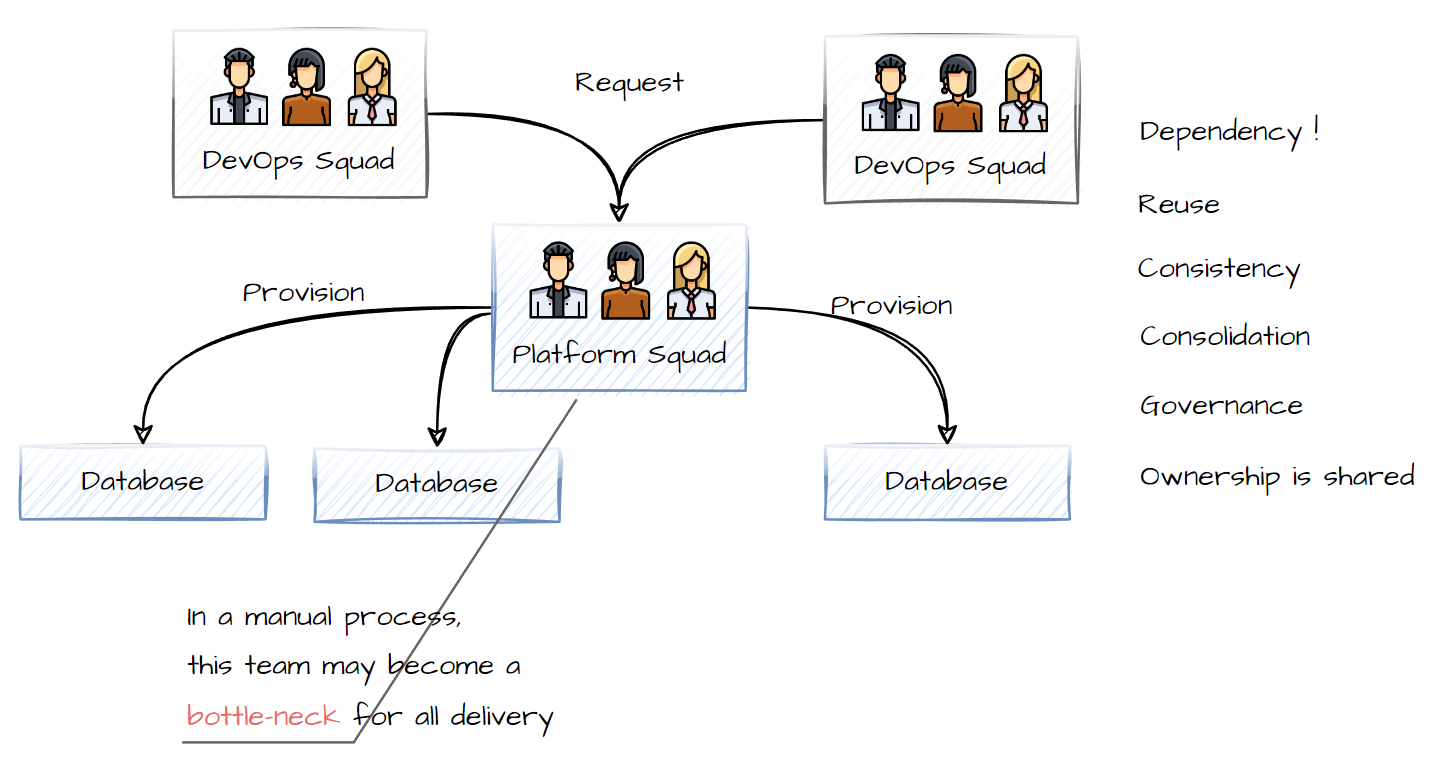
However, they find that no Squad can do work without having to invole the central Squad. this causes a bottleneck to delivery and hinders a scaleout to the number of Squads.
Taking the example. Squad A require a Postgres database, they have to request this with the Central squad. This could overwhelm the platform squad, as we scale out the Product squads (devops squads)
2 extremes
Both this examples are extremes, we need to find a way to empower squads while not blocking them or overloading them with technology.
Enter in self-service
We need a way for teams to just be able to specify the minimum, and for the number of software qualites to be taken care of.
Using Desired State technologies such as Kubernetes Operators (buid to automate) or Terraform Modules
We can ceate a Resource (module) which allows Squads to provision databases indipendently.
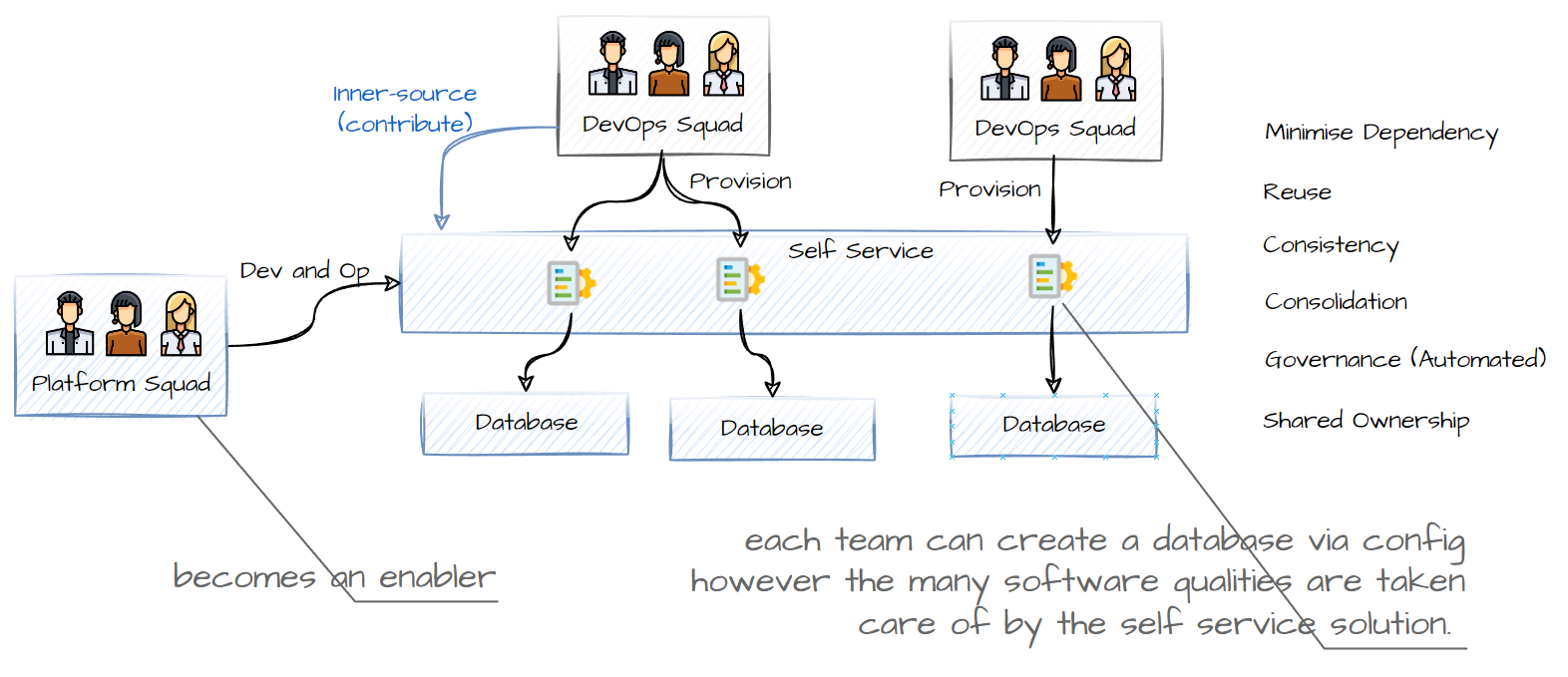
Example
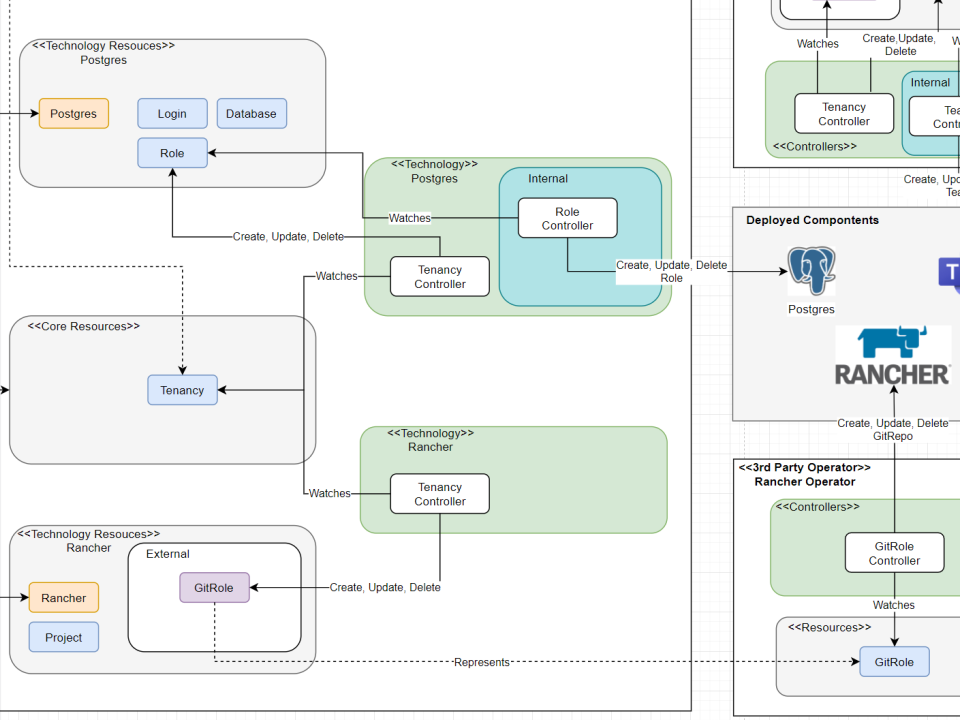
A project called lab.dev* aims at providing the self-service solution.
The Galaxy Squad defines the billing service (via a Service Resource).
lab.dev, creates
- a
billingdatabase on thespikecluster - a
billingnamespace and secret is created on theaquacluster
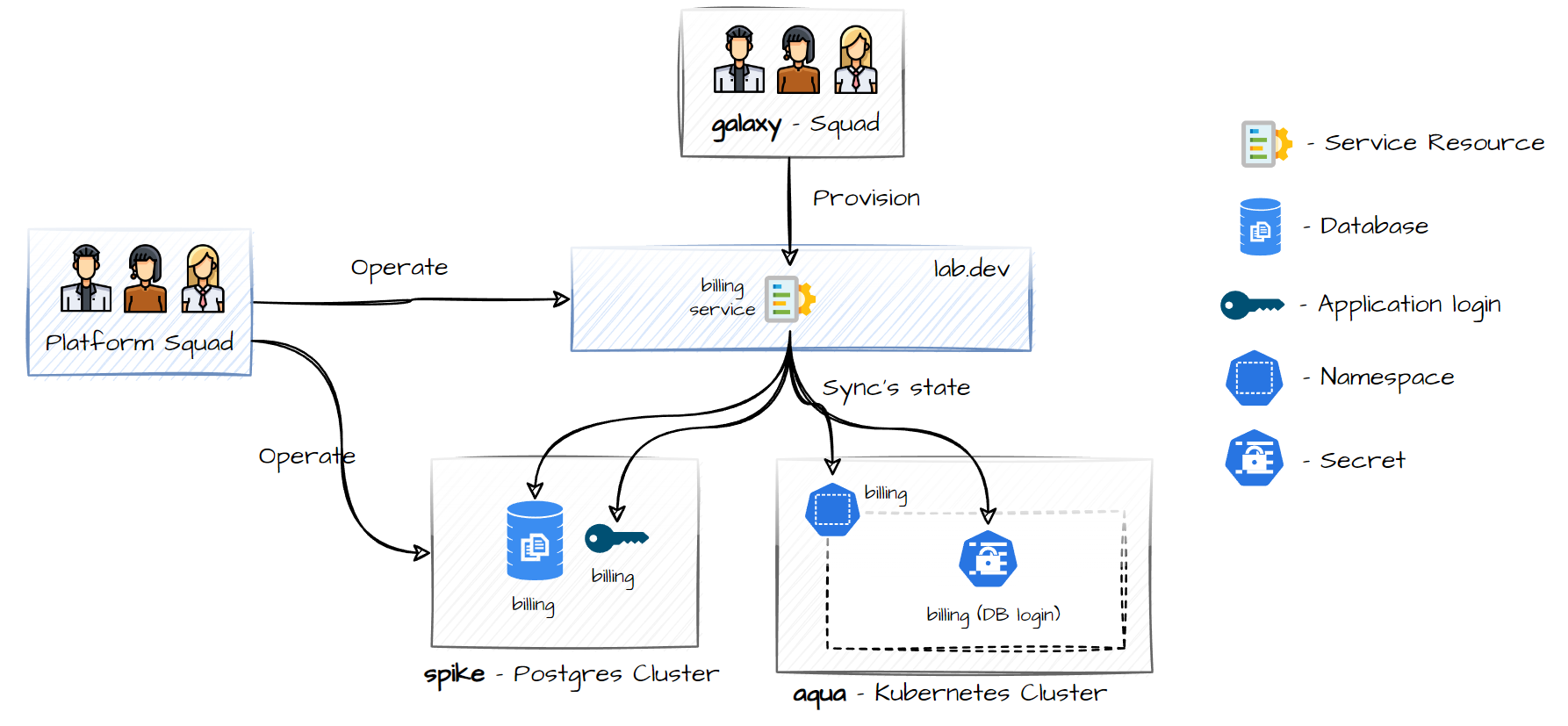
(this will include all the accounts, rbac, across multiple components)
To highlight, this is what the team creates
apiVersion: lab.dev/v1
kind: Service
metadata:
name: billing
namespace: galaxy
spec:
zones:
- name: frontier
components:
- name: spike # this will create a db and credentials
provider: postgres
- name: aqua # setup the namespace, and access for deployments
provider: kubernetes
Assumption- all delivery is via
GitOpsand all release has 4-eyes via Pull Requests. (which will apease some companies)
Observation
This technique is not free, it requires a self-service component
however we can see benifits:
- Squads are independent to create resources (databases, services, etc)
- the Platform squad are not a bottle-neck
- All resources are provisioned inline with regulations and governance
- The platform squad can work with Squads to add new features (inner-source)
Links
*note lab.dev is a project from me, and its a Work in progress
