TDD an IoC container - part 3 - Performance Refactor
using TDD to develop a simple IoC container.
- TL;DR;
- catch-up
- Benchmarking
- Replace the reflection invocation
- A new challanger
- Pulling this together. (2848 => 243)
This post series looks into how I apply TDD in order to have confidence in what is developed.
In this post I wanted to jump to a fun subject of writing an IoC container, and that is performance. We will look into some refactoring which will improve our performance, and use our tests to ensure we still provide the required service.
NOTE: in this post we are looking into microseconds (uS) and nanoseconds (nS), normal application code should not need to go to these lengths.
TL;DR;
- create a set of benchmarks, run them before any change to get a baseline and after to confirm return on investment
- any refactoring should not break out TDD tests
- reflection is slow
- compiled Expressions can provide IL type speeds
- every thing you do costs time, tracking, lookups etc, write the code to be a little more cleaver.
catch-up
At this point we have
- confirmed how the tests should drive the code (at the moment i would say this is mostly followed, running at 80% code coverage)
- since the last post most of the requirements have been met (90% tests are green), we have a few of the more complex requirements to cover still.
- the internal code may not be the cleanest (yet)
Benchmarking
In order:
- to know we have improvements, we need to have a baseline measure
- to know if we are performing well we need to have some competition which we can compete against.
In .Net, we have a framework/tool called DotNetBenchMark which allows us to setup a test, which it runs continuously in order to measure the performance (benchmark the code).
Each benchmark which will measure a number of scenarios. in our case, we have 4
- Transient
- Singleton
- Scoped
- Mixed
These should test how we create objects, from the calling the ctor, finding the contract, checking the instance cache and so on.
We started with Castle Windsor and Autofac, 2 very respected containers. In the later tests we added Grace (holy cow that is a fast container)
Replace the reflection invocation
A known easy win for us was to look at how the instances are created, we started with Reflection, which is known to be slow.
there are 3 things to do here:
- measure our current speed (get that actual baseline)
- what to use instead of reflection
- what code do we need to replace.
Step 1 - current speed.
We have executed an initial run on the benchmarks. which showed some interesting outputs
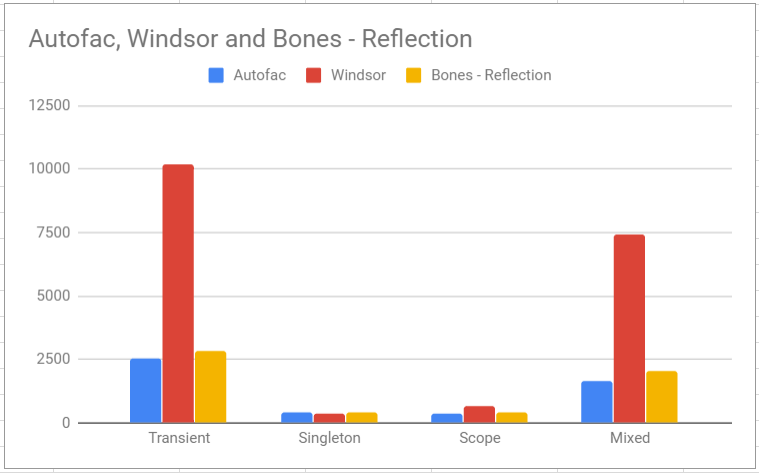
from this we can say
-
the initial implementation looks to be competitive to Autofac, howsoever the other 2 frameworks offer way more functionality.
-
windsor seems to do something better when it comes to singletons.
overall im a bit surprised by the performance, i would have thought Bones IoC would have been slower.
Step 2 - alternatives to reflection
An easy win to improve our speed is to use an alternative solution to create objects with, as we all know reflection is slow (as you can see from below).
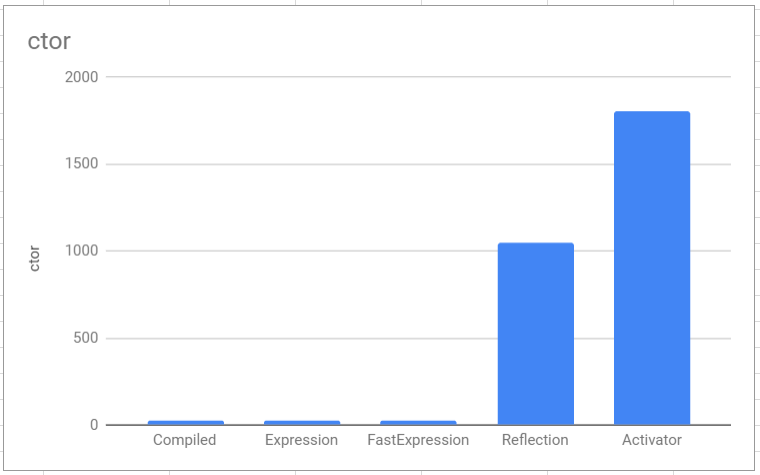
from this we can say
-
the compile code and expressions are almost the same speed around 25 nS, with 2 nanoseconds between them.
-
reflection is orders of magnitude slower.
-
activator …..
note that we do not need to check out the IL, as the complied expressions seemed to provide similar speeds to compiled C#
Step 3 - refactor
From the previous step we should be able to shave off a lot of time (1 microsecond) by just replacing a few lines of code.
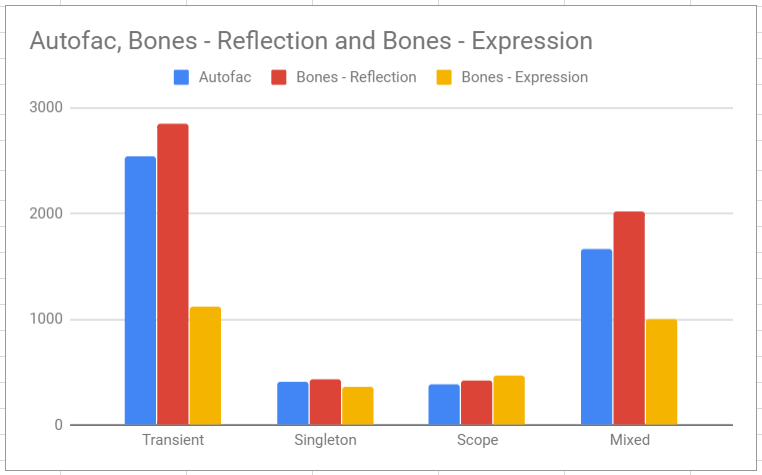
As you can see, this chart shows exactly what we wanted, a nice improvement
We did this by replacing/refactoring the delegate builder method, and by re-running the functional and benchmark tests we confirmed that we are in a better spot.
A new challanger
Taking the trasient benchmark we are at 1.1 uS (microseconds) however if we look at creating objects without any IoC intervention it was at 24 nS (nanoseconds). Where is the gap and can it be closed?
Grace, this is another IoC container, I would categorize it as one of the new generation.
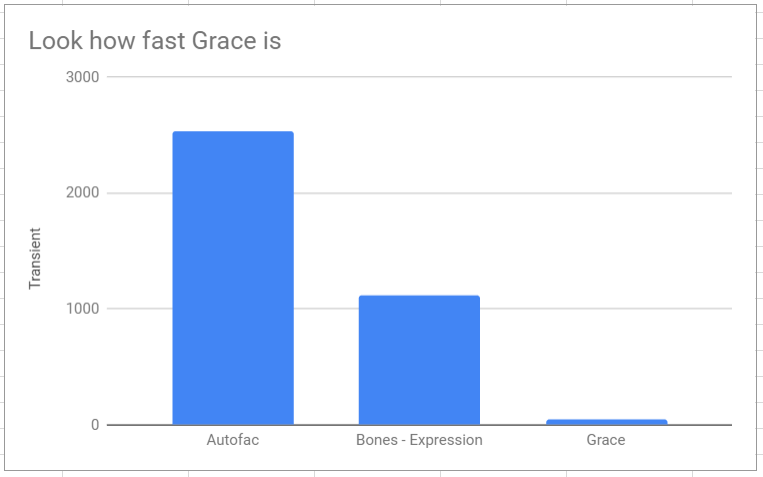
Look at these perf stats, this proves that we can narrow the gap, but how?
Here are some things that cost time (note we are looking at nanoseconds):
- Tracking items
- Instance Cache - skipping for now.
- Contract Registry
- Scope strategies
- Guards (Code.Require)
We need all of these components, so its a case of how and when.
Lets start by removing/disabling parts of the pipeline to identify where the ROI is
Tracking items - Cost: 525.50~ nS
Each scope implements a tracking feature, which will ensure post actions such as disposal is taken care of on the disposal of the scope.
The current implementation is using the Stack<T>, this ensures the correct order in which to unwind the scope with.
When we remove the 1 line of code (pushing onto the tracking stack) we get a significant improvement, around 45%.
Solution: lazy-ly add items to be tracked. also look into alternative to a stack (maybe a linked list).
Guards - Cost: 209.77~ nS
A few of the internal methods utilise our Code.Require functionality. A simple predicate to ensure a pre-condition is met.
As the code is internal, we could surmise that they are protected by external contract being upheld and validated during registration.
When we remove 3 of these checks, we see another improvement of 18%.
Solution: confirm the stability if these are removed. THIS IS NOT IDEAL
Scope strategies - Cost: 26.93~ nS
Only looking at the transient strategy (keeping it simple), it creates a Instance object which is responsible for storing the resolved value along with its contract, this is used to dispose of the resolved value correctly.
The current implementation cost a small amount of time, which looks to be around 3%.
Solution: Look into using a pre-generated delegate, and remove the Instance class
Contract Registry - Cost: 158.53~ nS
Each Resolve uses a ServiceKey’s hash in-order to find the contract from a dictionary, this is should be fast, with a O(1). Where the contract contains all the information on how to create an instance.
//this is what the internal generated delegate would look like
return new Service(scope.Resolve(repoServiceKey), scope.Resolve(loggerServiceKey));
Removing this dictionary lookup, so it uses references the contract directly, like so:
//this is what the internal generated delegate would look like
return new Service(scope.Resolve(repoContract), scope.Resolve(loggerContract));
this showed that 13% can be saved here.
Solution: continue with this code, refactor it (tidy up)
ServiceKey as a Struct - Negative improvement
At the moment the servicekey is a class, it needs to be created quickly to be used as the initial lookup.
Converting this to a struct should increase the initial lookup performance…
This small change seemed to add to the count (ran the test twice). for now i will leave this.
Pulling this together. (2848 => 243)
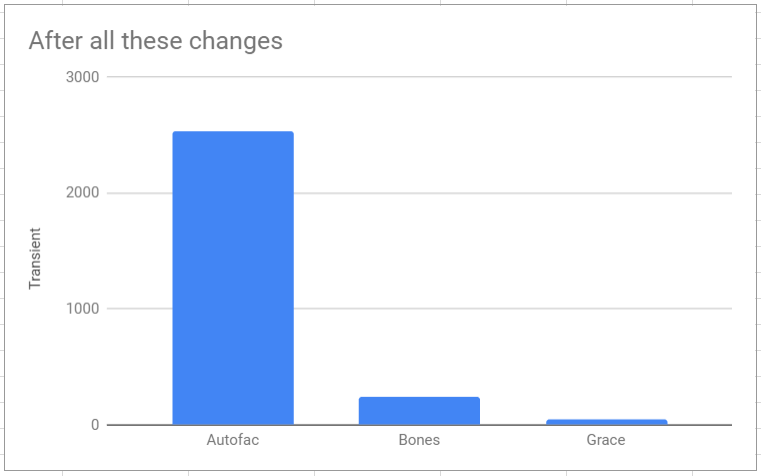
We did not hit the Ultra-Fast speed of Grace, however we have implemented a significant improvement.
I have noticed that some of the other containers use their own collections in order to gain performance increases form AVL to HashTables.
However we did find several area’s which will significantly improve the performance.
The winner items here were the compiled Expressions and tracking.
Concurrency access to the instance cache and an alternative to tracking has not been fully looked into. (may do a separate post on these).
